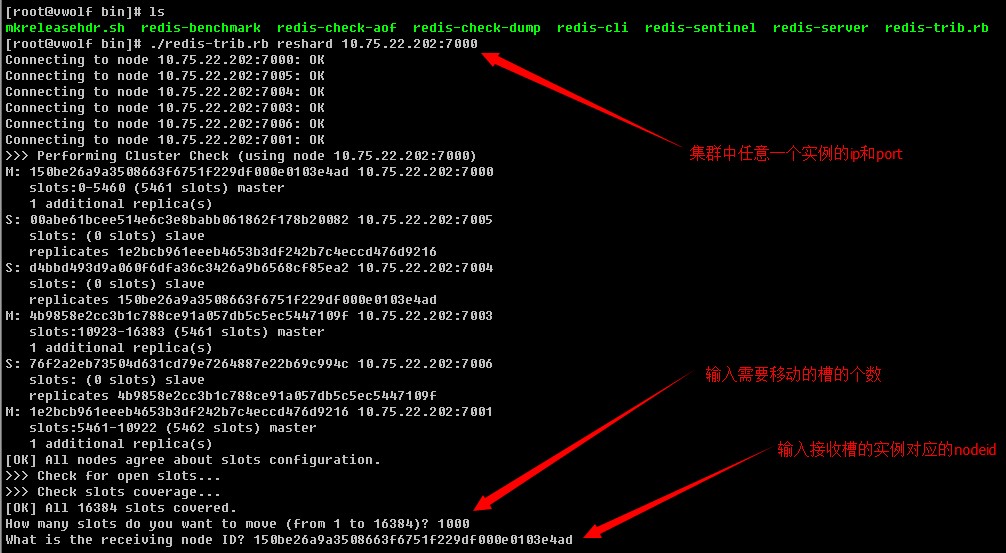
redis-trib.rb reshard 10.75.22.202:7000
#根据提示选择要迁移的slot数量(ps:这里选择1000)
How many slots do you want to move (from 1 to 16384)? 1000
#选择要接受这些slot的node-id
What is the receiving node ID? 150be26a9a3508663f6751f229df000e0103e4ad
#选择slot来源:
#all表示从所有的master重新分配,
#或者数据要提取slot的master节点id,最后用done结束
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:all
#打印被移动的slot后,输入yes开始移动slot以及对应的数据.
#Do you want to proceed with the proposed reshard plan (yes/no)? yes
#结束
6.6 添加slave节点
其他类似,命令改成下面改样:
./redis-trib.rb add-node --slave 10.75.22.202:7007 10.75.22.202:7000
执行成功后,7007将作为7000的从库。
或者用另外一种方法:
新节点创建成功后,用redis-cli连接上新节点,然后执行下面的命令:
redis 10.75.22.202:7007> cluster replicate 150be26a9a3508663f6751f229df000e0103e4ad
其中150be26a9a3508663f6751f229df000e0103e4ad表示7000端口实例对应的nodeid,这样新建的7007实例将作为7000实例的从库。
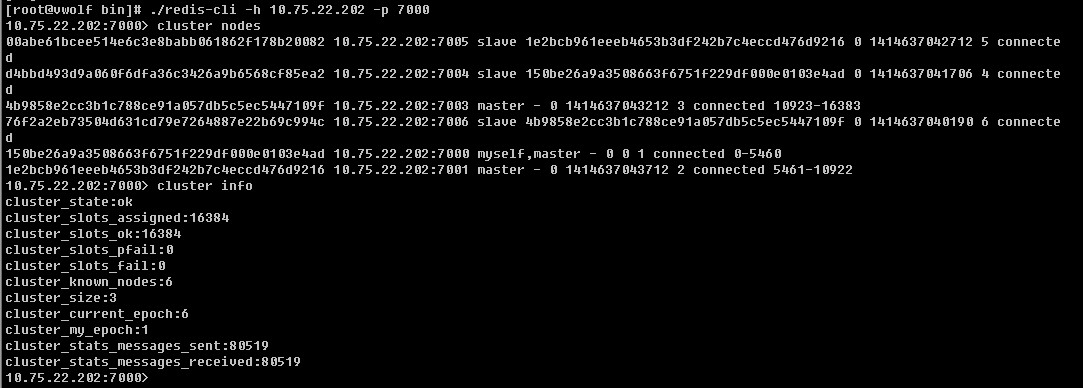
删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点(目前只能把被删除master的slot迁移到一个节点上)
#把10.75.22.202:7001当前master迁移到10.75.22.202:7000上
redis-trib.rb reshard 10.75.22.202:7000
#根据提示选择要迁移的slot数量(ps:这里选择4960)
How many slots do you want to move (from 1 to 16384)? 4960(被删除master的所有slot数量)
#选择要接受这些slot的node-id(10.75.22.202:7000)
What is the receiving node ID? 150be26a9a3508663f6751f229df000e0103e4ad (ps:10.75.22.202:7000的node-id)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:1e2bcb961eeeb4653b3df242b7c4eccd476d9216(被删除master的node-id)
Source node #2:done
#打印被移动的slot后,输入yes开始移动slot以及对应的数据.
#Do you want to proceed with the proposed reshard plan (yes/no)? yes
上述操作执行成功后,master节点上面已经没有数据了,这时候可以像删除slave节点一样删除master节点:
./redis-trib.rb del-node 10.75.22.202:7001 1e2bcb961eeeb4653b3df242b7c4eccd476d9216
import copy
a = range(100000)
%timeit -n 10 copy.copy(a) # 运行10次 copy.copy(a)
%timeit -n 10 copy.deepcopy(a)
10 loops, best of 3: 1.55 ms per loop
10 loops, best of 3: 151 ms per loop
a = range(1000)
s = set(a)
d = dict((i,1) for i in a)
%timeit -n 10000 100 in d
%timeit -n 10000 100 in s
10000 loops, best of 3: 43.5 ns per loop
10000 loops, best of 3: 49.6 ns per loop
dict的效率略高(占用的空间也多一些)。
5.合理使用生成器(generator)和yield
1234
%timeit -n 100 a = (i for i in range(100000))
%timeit -n 100 b = [i for i in range(100000)]
100 loops, best of 3: 1.54 ms per loop
100 loops, best of 3: 4.56 ms per loop
使用()得到的是一个generator对象,所需要的内存空间与列表的大小无关,所以效率会高一些。在具体应用上,比如set(i for i in range(100000))会比set([i for i in range(100000)])快。
但是对于需要循环遍历的情况:
1234
%timeit -n 10 for x in (i for i in range(100000)): pass
%timeit -n 10 for x in [i for i in range(100000)]: pass
10 loops, best of 3: 6.51 ms per loop
10 loops, best of 3: 5.54 ms per loop
def yield_func(ls):
for i in ls:
yield i+1
def not_yield_func(ls):
return [i+1 for i in ls]
ls = range(1000000)
%timeit -n 10 for i in yield_func(ls):pass
%timeit -n 10 for i in not_yield_func(ls):pass
10 loops, best of 3: 63.8 ms per loop
10 loops, best of 3: 62.9 ms per loop
对于内存不是非常大的list,可以直接返回一个list,但是可读性yield更佳(人个喜好)。
python2.x内置generator功能的有xrange函数、itertools包等。
6.优化循环
循环之外能做的事不要放在循环内,比如下面的优化可以快一倍:
123456
a = range(10000)
size_a = len(a)
%timeit -n 1000 for i in a: k = len(a)
%timeit -n 1000 for i in a: k = size_a
1000 loops, best of 3: 569 µs per loop
1000 loops, best of 3: 256 µs per loop
7.优化包含多个判断表达式的顺序
对于and,应该把满足条件少的放在前面,对于or,把满足条件多的放在前面。如:
123456789
a = range(2000)
%timeit -n 100 [i for i in a if 10 < i < 20 or 1000 < i < 2000]
%timeit -n 100 [i for i in a if 1000 < i < 2000 or 100 < i < 20]
%timeit -n 100 [i for i in a if i % 2 == 0 and i > 1900]
%timeit -n 100 [i for i in a if i > 1900 and i % 2 == 0]
100 loops, best of 3: 287 µs per loop
100 loops, best of 3: 214 µs per loop
100 loops, best of 3: 128 µs per loop
100 loops, best of 3: 56.1 µs per loop
8.使用join合并迭代器中的字符串
1234567891011
In [1]: %%timeit
...: s = ''
...: for i in a:
...: s += i
...:
10000 loops, best of 3: 59.8 µs per loop
In [2]: %%timeit
s = ''.join(a)
...:
100000 loops, best of 3: 11.8 µs per loop
join对于累加的方式,有大约5倍的提升。
9.选择合适的格式化字符方式
1234567
s1, s2 = 'ax', 'bx'
%timeit -n 100000 'abc%s%s' % (s1, s2)
%timeit -n 100000 'abc{0}{1}'.format(s1, s2)
%timeit -n 100000 'abc' + s1 + s2
100000 loops, best of 3: 183 ns per loop
100000 loops, best of 3: 169 ns per loop
100000 loops, best of 3: 103 ns per loop
三种情况中,%的方式是最慢的,但是三者的差距并不大(都非常快)。(个人觉得%的可读性最好)
10.不借助中间变量交换两个变量的值
1234567891011
In [3]: %%timeit -n 10000
a,b=1,2
....: c=a;a=b;b=c;
....:
10000 loops, best of 3: 172 ns per loop
In [4]: %%timeit -n 10000
a,b=1,2
a,b=b,a
....:
10000 loops, best of 3: 86 ns per loop
使用a,b=b,a而不是c=a;a=b;b=c;来交换a,b的值,可以快1倍以上。
11.使用if is
12345
a = range(10000)
%timeit -n 100 [i for i in a if i == True]
%timeit -n 100 [i for i in a if i is True]
100 loops, best of 3: 531 µs per loop
100 loops, best of 3: 362 µs per loop
使用 if is True 比 if == True 将近快一倍。
12.使用级联比较x < y < z
12345
x, y, z = 1,2,3
%timeit -n 1000000 if x < y < z:pass
%timeit -n 1000000 if x < y and y < z:pass
1000000 loops, best of 3: 101 ns per loop
1000000 loops, best of 3: 121 ns per loop
x < y < z效率略高,而且可读性更好。
13.while 1 比 while True 更快
12345678910111213141516
def while_1():
n = 100000
while 1:
n -= 1
if n <= 0: break
def while_true():
n = 100000
while True:
n -= 1
if n <= 0: break
m, n = 1000000, 1000000
%timeit -n 100 while_1()
%timeit -n 100 while_true()
100 loops, best of 3: 3.69 ms per loop
100 loops, best of 3: 5.61 ms per loop
while 1 比 while true快很多,原因是在python2.x中,True是一个全局变量,而非关键字。
14.使用**而不是pow
1234
%timeit -n 10000 c = pow(2,20)
%timeit -n 10000 c = 2**20
10000 loops, best of 3: 284 ns per loop
10000 loops, best of 3: 16.9 ns per loop
import cPickle
import pickle
a = range(10000)
%timeit -n 100 x = cPickle.dumps(a)
%timeit -n 100 x = pickle.dumps(a)
100 loops, best of 3: 1.58 ms per loop
100 loops, best of 3: 17 ms per loop
由c实现的包,速度快10倍以上!
16.使用最佳的反序列化方式
下面比较了eval, cPickle, json方式三种对相应字符串反序列化的效率:
123456789101112
import json
import cPickle
a = range(10000)
s1 = str(a)
s2 = cPickle.dumps(a)
s3 = json.dumps(a)
%timeit -n 100 x = eval(s1)
%timeit -n 100 x = cPickle.loads(s2)
%timeit -n 100 x = json.loads(s3)
100 loops, best of 3: 16.8 ms per loop
100 loops, best of 3: 2.02 ms per loop
100 loops, best of 3: 798 µs per loop
13.校验 a in b, 字典 或 set 比 列表 或 元组 更好
14.当数据量大的时候,尽可能使用不可变数据类型,他们更快 元组 > 列表
15.在一个列表中插入数据的复杂度为 O(n)
16.如果你需要操作列表的两端,使用 deque
17.del – 删除对象使用如下
1) python 自己处理它,但确保使用了 gc 模块
2) 编写 del 函数
3) 最简单的方式,使用后调用 del
18.time.clock()
19.GIL(http://wiki.python.org/moin/GlobalInterpreterLock) – GIL is a daemon
GIL 仅仅允许一个 Python 的原生线程来运行每个进程。阻止 CPU 级别的并行,尝试使用 ctypes 和 原生的 C 库来解决它,当你达到 Python 优化的最后,总是存在一个选项,可以使用原生的 C 重写慢的函数,通过 Python 的 C 绑定使用它,其他的库如 gevent 也是致力于解决这个问题,并且获得了成功。
TL,DR:当你写代码了,过一遍数据结构,迭代结构,内建和为 GIL 创建 C 扩展,如有必要。
更新:multiprocessing 是在 GIL 的范围之外,这意味着你可以使用 multiprocessing 这个标准库来运行多个进程。
def gen():
for n in xrange(5):
yield n
g = gen()
print g # <generator object gen at 0x...>
print g.gi_code # <code object gen at 0x...>
print g.gi_frame # <frame object at 0x...>
print g.gi_running # 0
print g.next() # 0
print g.next() # 1
for n in g:
print n, # 2 3 4
对于实现了call的类实例,这个方法会返回False。如果目的是只要可以直接调用就需要是True的话,不妨使用isinstance(obj, collections.Callable)这种形式。我也不知道为什么Callable会在collections模块中,抱歉!我猜大概是因为collections模块中包含了很多其他的ABC(Abstract Base Class)的缘故吧:)
def authenticated(method):
"""Decorate methods with this to require that the user be logged in."""
@functools.wraps(method)
def wrapper(self, *args, **kwargs):
if not self.current_user:
if self.request.method in ("GET", "HEAD"):
url = self.get_login_url()
if "?" not in url:
if urlparse.urlsplit(url).scheme:
# if login url is absolute, make next absolute too
next_url = self.request.full_url()
else:
next_url = self.request.uri
url += "?" + urllib.urlencode(dict(next=next_url))
self.redirect(url)
return
raise HTTPError(403)
return method(self, *args, **kwargs)
return wrapper
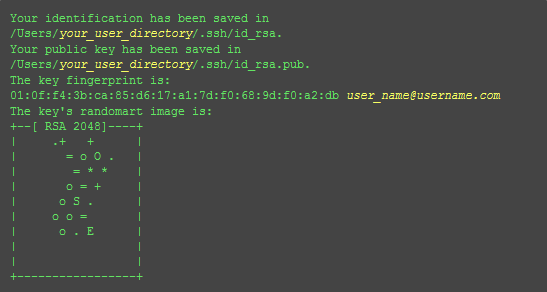
$ ssh-keygen -t rsa -C "邮件地址@youremail.com"
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/your_user_directory/.ssh/id_rsa):<回车就好>
The authenticity of host 'github.com (207.97.227.239)' can't be established.
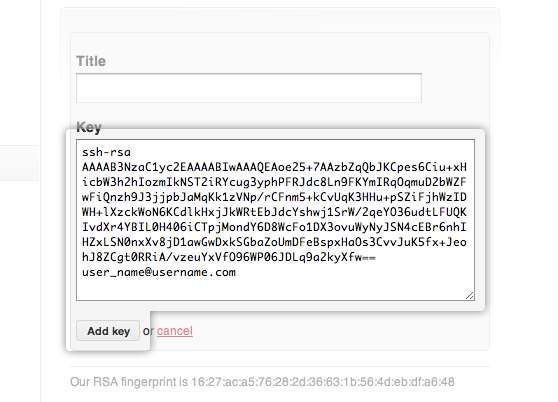
RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
Are you sure you want to continue connecting (yes/no)?
不要紧张,输入yes就好,然后会看到:
Hi <em>username</em>! You've successfully authenticated, but GitHub does not provide shell access.
git clone git://github.com/imathis/octopress.git octopress
cd octopress # If you use RVM, You'll be asked if you trust the .rvmrc file (say yes).
ruby --version # Should report Ruby 1.9.2
然后安装依赖:
123
gem install bundler
rbenv rehash # If you use rbenv, rehash to be able to run the bundle command
bundle install
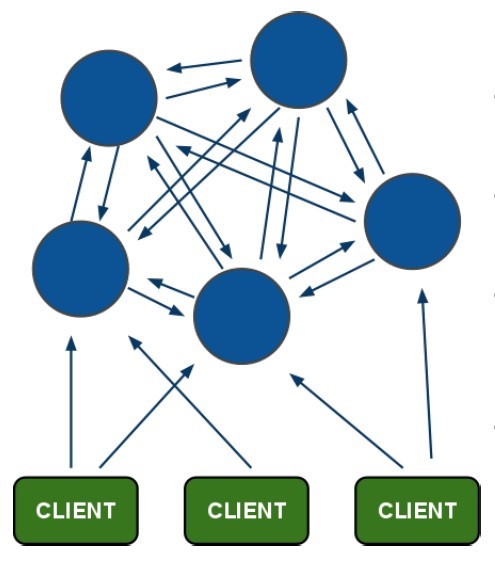
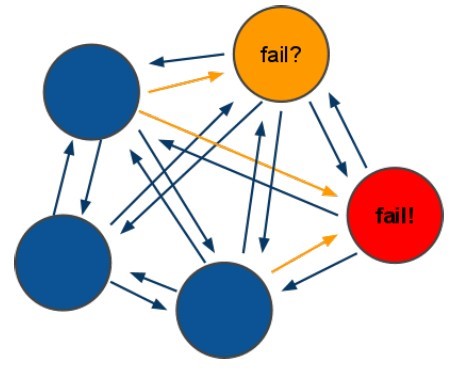
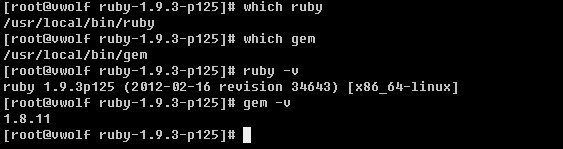




 而普通的项目是这样的,即使你也是用的
而普通的项目是这样的,即使你也是用的